Ingesting knowledge (content)
In this chapter you'll teach the agent everything it needs to know about your business. By the end, the team's knowledge base will hold a set of documents the agent can search and cite during conversations.
There are two ways to get content into the platform:
- Map and scrape a website — discover all the pages on a public website and import the ones you want.
- Upload documents — push files (Markdown, PDF, Word, etc.) into the knowledge base directly.
Both routes feed the same downstream pipeline: the platform classifies the document, chunks it intelligently, extracts attributes, and embeds each chunk as a vector so retrieval can find it later.
We'll cover both routes, plus the Attributes screen that lives next to them.
Where the content lives
Open the team's Content section from the left-hand rail. For a brand-new team the screen is empty.
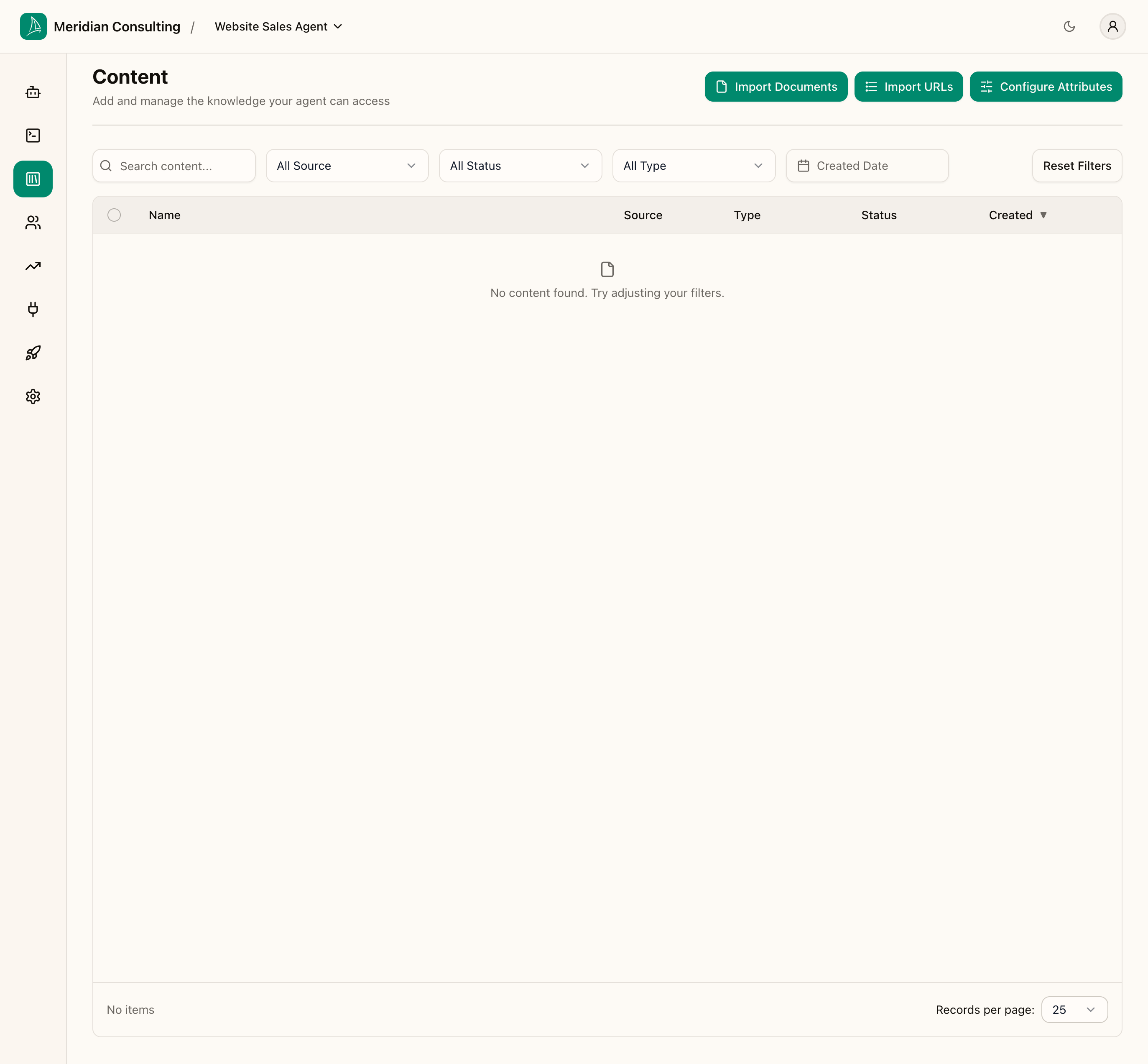
You get three primary buttons:
- Import Documents — opens the document-upload flow
- Import URLs — opens the map-and-scrape flow
- Configure Attributes — opens the attributes configuration screen
Below those, a search box and filter controls let you slice the content list by source, status, type, and date once you have items in it.
The columns of the data table are:
- Name — the URL or filename
- Source —
websitefor scraped URLs,documentfor uploads - Type — what the platform classified the content as (see How the platform classifies content, below)
- Status —
pending,processing,ready, orfailed - Created — when the item entered the platform
Importing from a website (map & scrape)
Click Import URLs. The page is a three-step flow:
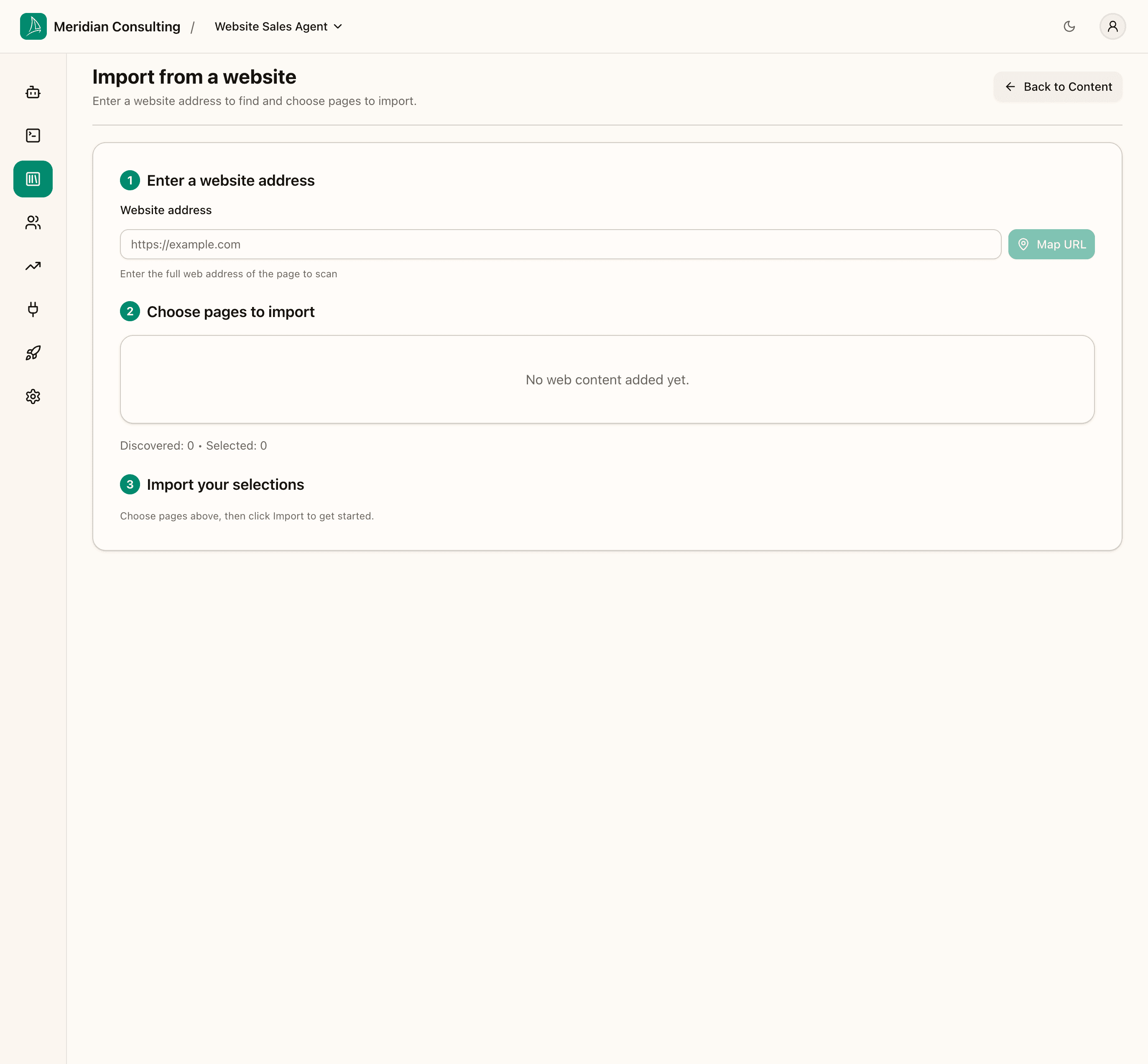
Step 1 — Enter a website address
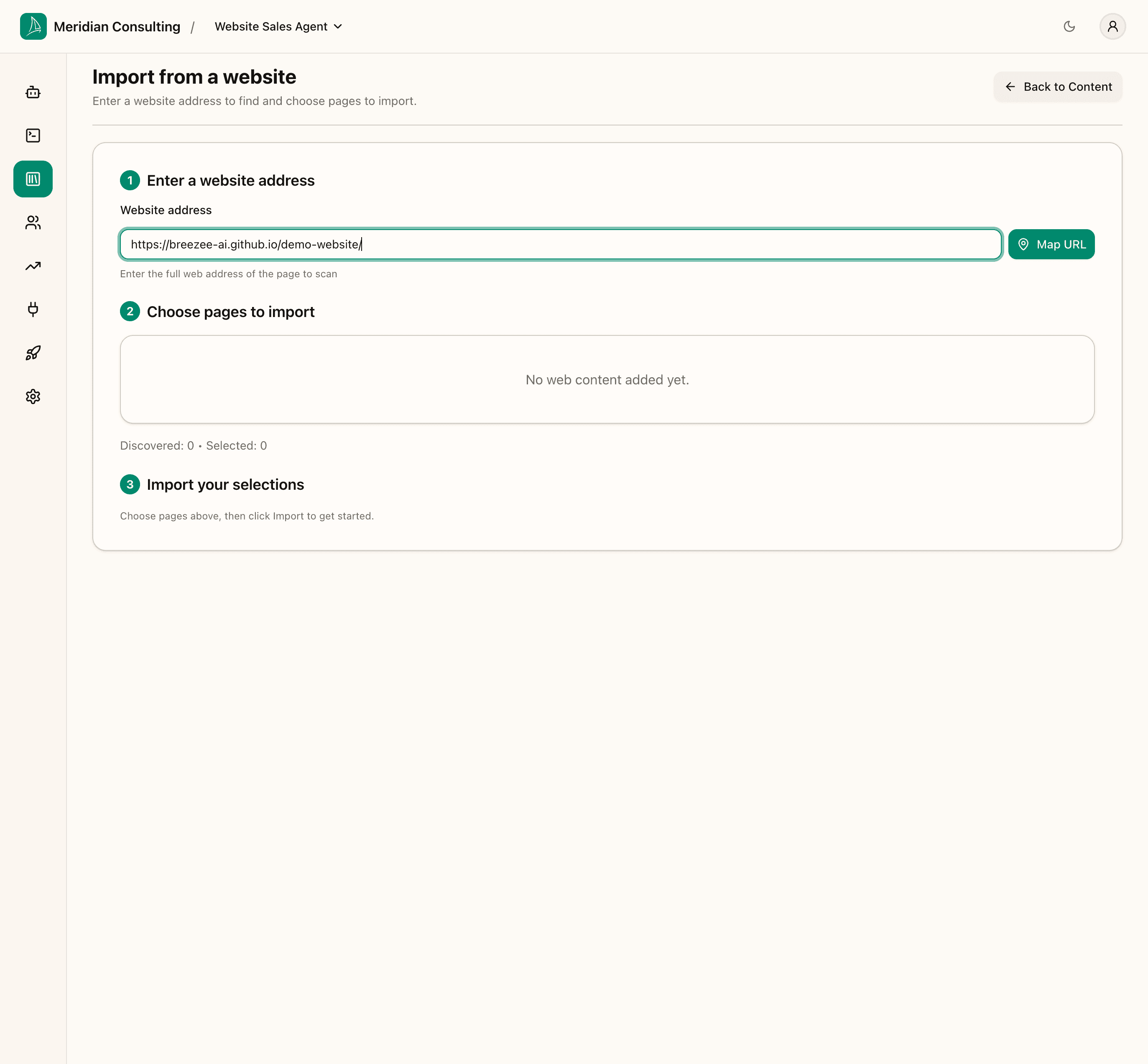
Paste the URL of the website you want to map and click Map URL. The platform uses Firecrawl to discover all reachable pages from that starting point.
In the example below we use the demo tenant's website:
While the map is running, the form shows a "Processing URL..." indicator with elapsed time:
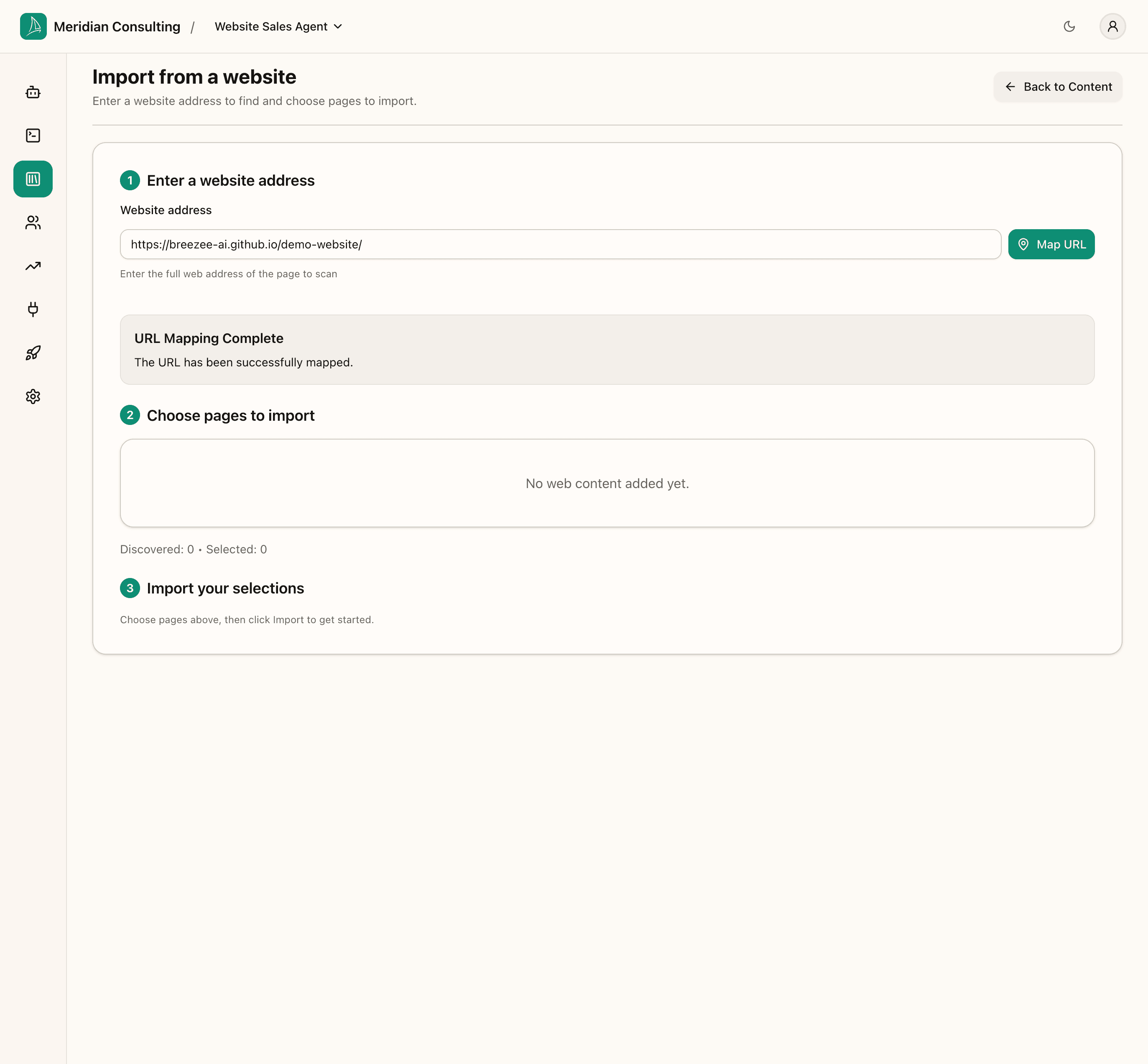
Step 2 — Choose pages to import
Once the map completes, the Choose pages to import section populates with the URLs Firecrawl discovered. You select the pages you want and watch the Selected counter increment.
Important: single-page sites return an empty discovered list. The URL mapper reports child pages reachable from the seed URL, not the seed itself. For multi-page sites (documentation sites, product catalogues, corporate sites with dozens of pages) the Step 2 list populates with checkboxes for each discovered URL. Use Select all when you want every page; cherry-pick when you want a subset.
Step 3 — Import your selections
Click Import to push the selected URLs into the pipeline. Each URL becomes a website row in the Content list, moves through pending → processing → ready, and once ready is fully chunked, attribute-extracted, and embedded.
Uploading documents
Click Import Documents.
Supported formats are listed on the page itself: PDF, Word, Excel, PowerPoint, HTML, Markdown, RTF, and plain text. Per-file limit is 5 MB.
Drag files onto the drop zone, or click the zone to open the file picker. You can stage multiple files in one go.
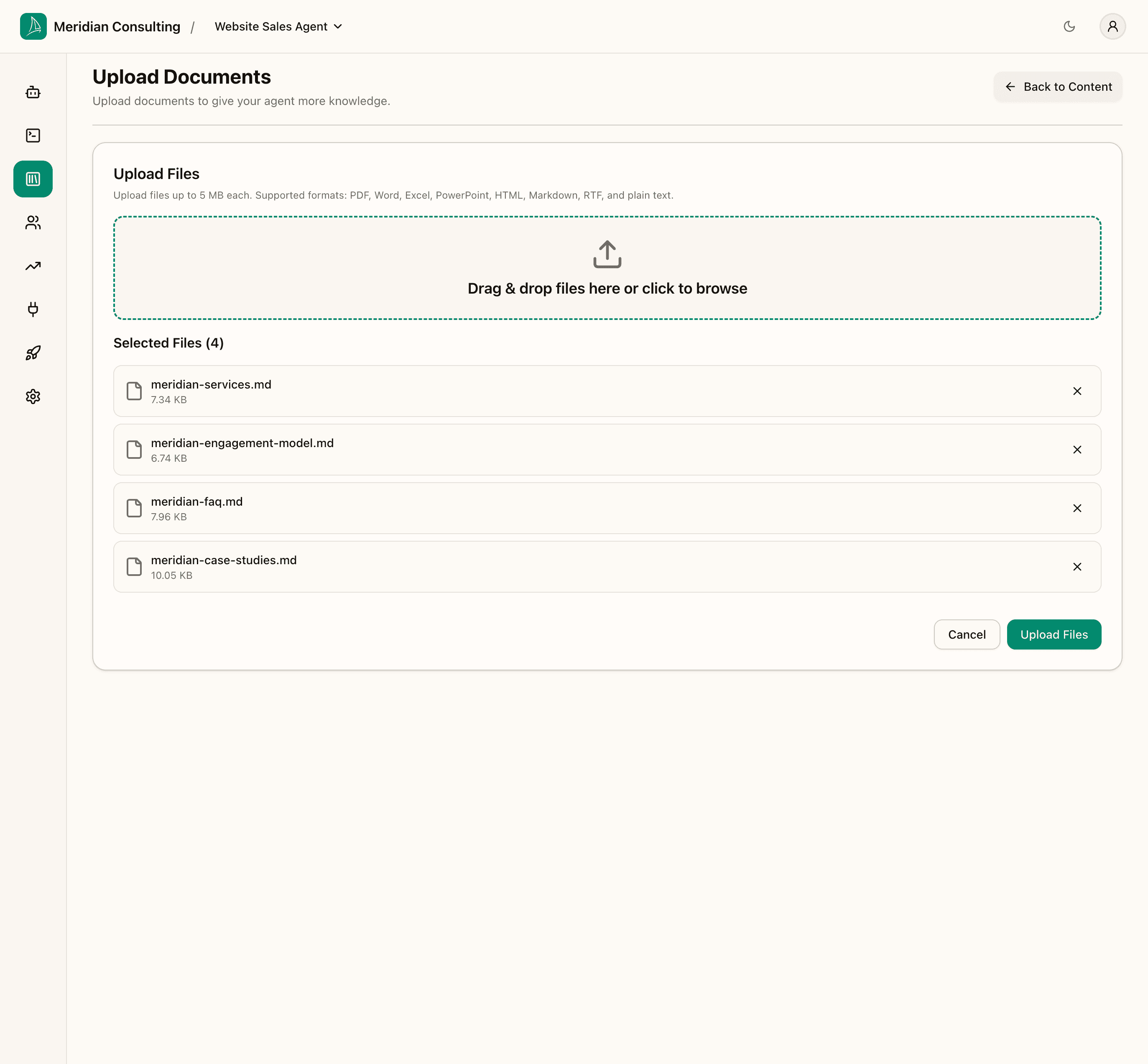
Click Upload Files to commit them to the pipeline. The flow finishes immediately and returns you to the empty drop zone — the actual processing happens asynchronously.
Why upload Markdown when scraping the website would do?
Two reasons we'll see throughout the rest of the manual:
- The website may not contain the depth of knowledge the agent needs. The information surfaced on a marketing site is usually summary-level; the real knowledge — services in depth, engagement model, FAQ, case studies — often lives in documents authored specifically for the agent to consume.
- Uploaded documents are easier to control. You write them, you version them, you know what they say. Scraped pages reflect whatever's live on the public site — useful, but not always what you want the agent grounded in.
In production tenants you'll usually use both: scrape the public site for breadth, upload authored documents for depth.
What the pipeline does after ingest
Once a content item enters the platform — whether scraped or uploaded — it moves through several stages before it's ready for the agent to use.
| Stage | What happens |
|---|---|
| Parse | The raw file is converted to text. PDFs and Office documents go through Unstructured.io; Markdown is consumed natively. |
| Classify | The platform decides what kind of content this is — product, knowledge, company, etc. The classification influences how it'll be retrieved later. |
| Chunk | The text is split into self-contained chunks. The chunker is AI-driven; it tries to keep semantically coherent passages together rather than splitting on raw token counts. For an FAQ-style document, each Q&A typically becomes its own chunk. |
| Extract attributes | Structured attributes (see next section) are pulled out of each chunk. |
| Embed | Each chunk is converted to a 1536-dimensional vector for similarity search. |
While these stages run, the content item's Status column moves from pending → processing → ready. The pipeline runs asynchronously, so you can ingest more content in parallel and move on to other configuration work.
How the platform classifies content
You'll see the Type column take different values depending on what the platform thinks each document is. In the example shown, the four uploads classified as:
| File | Type |
|---|---|
meridian-services.md | product |
meridian-engagement-model.md | product |
meridian-faq.md | knowledge |
meridian-case-studies.md | company |
Three different types from four documents. The classifier reads the content rather than the filename, so a "FAQ" document is recognised as knowledge regardless of what you call the file, and a case-studies document is recognised as company (general organisational context) rather than product information.
These types matter at retrieval time. The platform's retrieval policies (covered in the agent's behaviour, not in this chapter) weight different content types differently — for example, the informational policy has an FAQ priority fast-path that short-circuits to high-similarity FAQ chunks before running the full search.
Inspecting ingested content
Back on the Content list, the four uploaded files now show ready status:
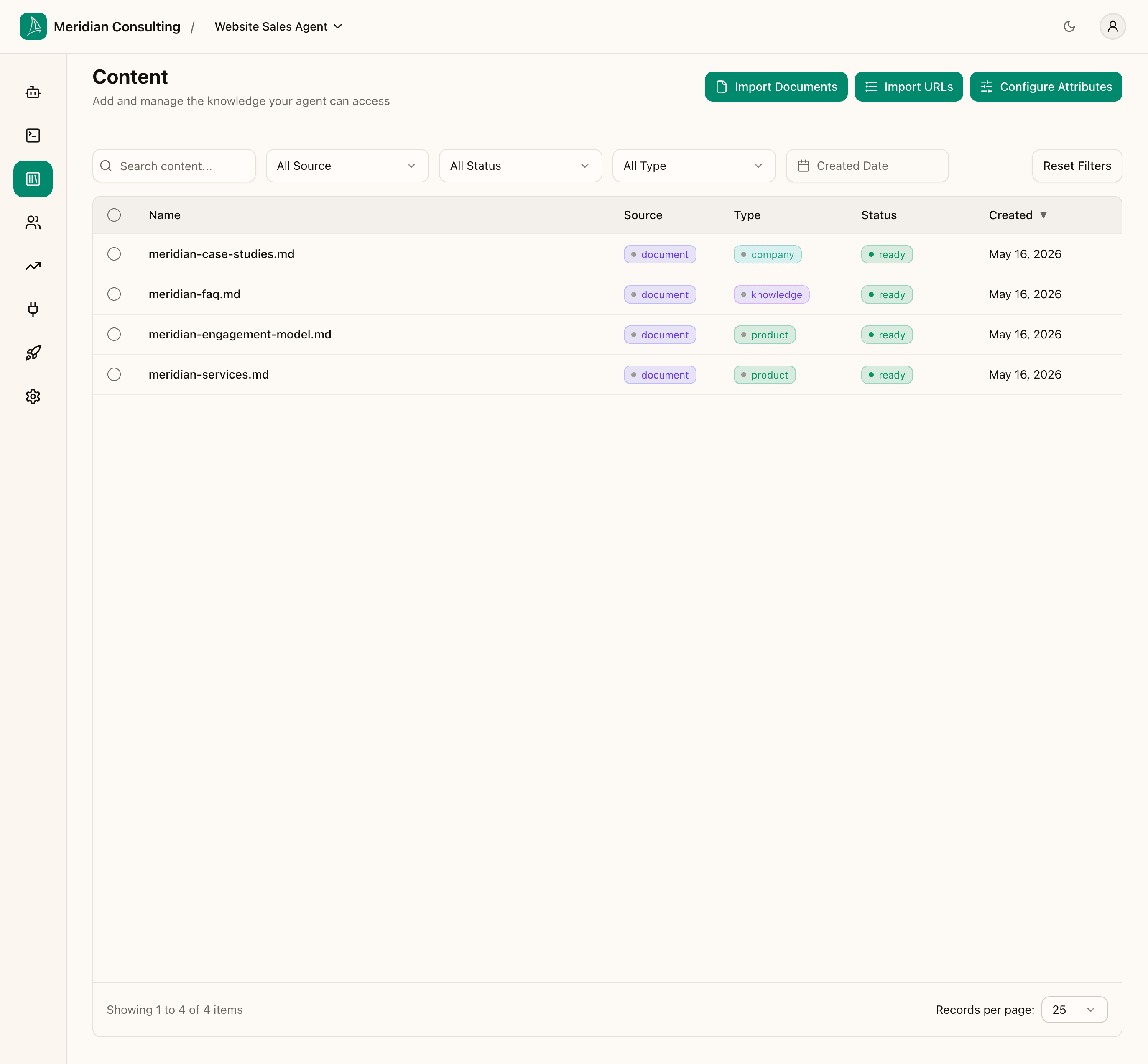
Click any row to open the detail panel on the right. The panel shows two sections:
- Attributes — the structured attributes extracted from this content (more on these below).
- Content Chunks — the chunks the pipeline produced, paginated. Each chunk shows its title, its type/subtype tags, and its body text.
For the FAQ document shown, the chunker produced 23 chunks — one per Q&A. The titles are recognisable as the questions themselves, which is what you want for FAQ-style content to retrieve well.
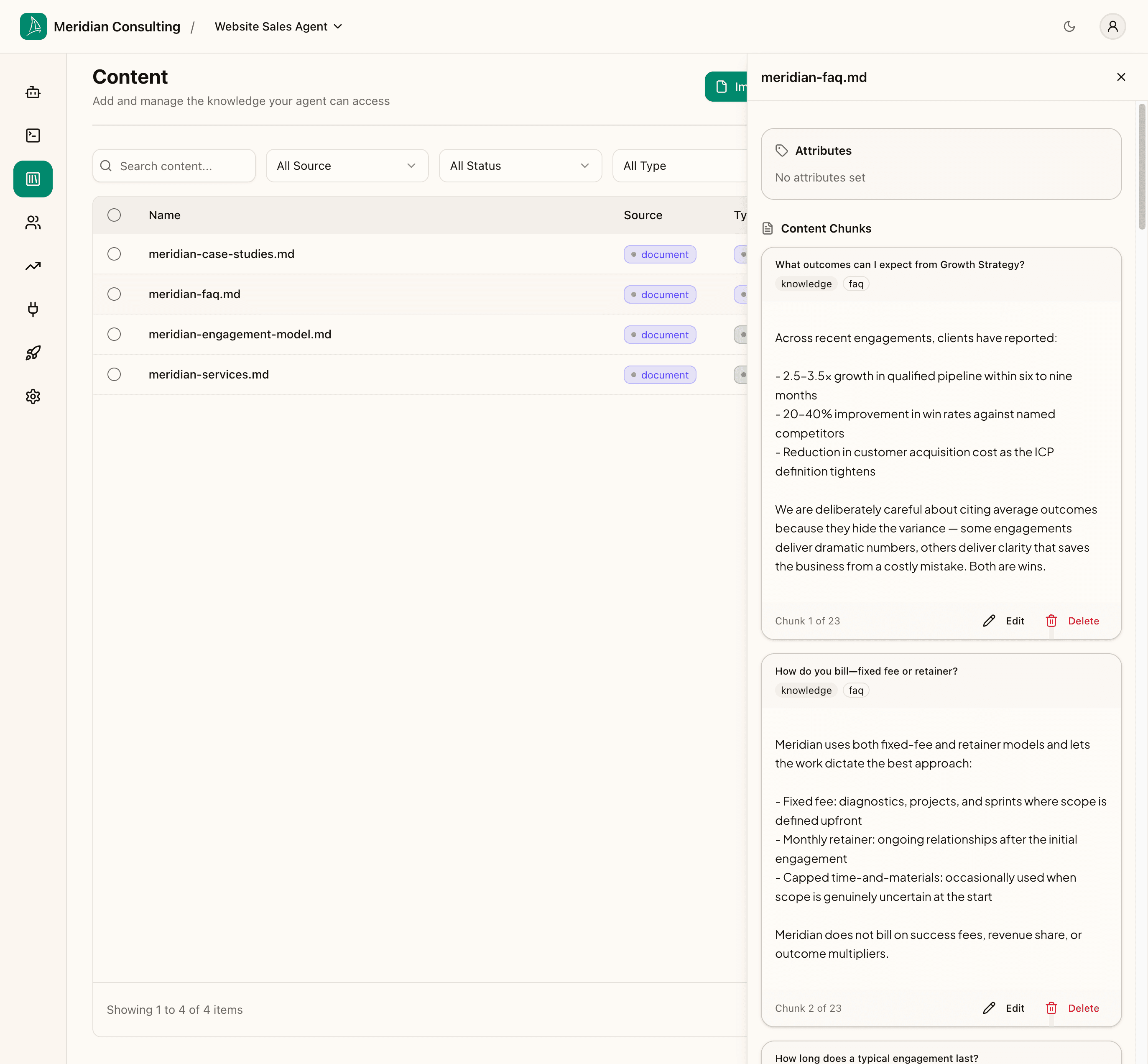
Each chunk has Edit and Delete buttons. Edit lets you adjust the body if the chunker miscategorised something; delete removes the chunk from the agent's available pool. You'll rarely need either in practice — the AI chunker handles most content well — but they're there when you need them.
Attributes (introduction only)
The Configure Attributes button takes you to the Product Attributes page.
This page lets you define a structured schema that gets extracted from your product content. For an e-commerce store, attributes might be things like colour, size, material, price_band, brand, style. For a SaaS product catalogue, they might be plan_tier, seat_count, region, integration_supported. The attribute schema feeds the agent's retrieval — when a visitor asks for "waterproof jackets under £150", the agent applies the structured attribute constraints rather than relying on the text match alone.
Important: attributes are only worth configuring for product-shaped catalogues. If your content describes discrete items with consistent structured properties — products with sizes, plans with tiers, parts with specs — define attributes here and the agent will use them to filter retrieval. If your content is services-shaped (long-form descriptions, FAQs, case studies) leave attributes alone; semantic similarity plus content-type classification will do the right thing without them. Configuring attributes on the wrong kind of content adds noise rather than precision.
What's next
Your knowledge base is populated. The agent now has something to draw on when visitors ask questions. The next step is to tell the platform what the agent should remember about each visitor — that's memory types, prospect profiles, and qualification, all configured before we attach skills to the agent.